Abstract
U-Net 已成为图像分割和扩散概率模型等各种视觉应用的基石。虽然通过结合transformer或 MLP,U-Net 已经引入了许多创新设计和改进,但仍然局限于线性建模模式,而且可解释性不足。为了应对这些挑战,我们的直觉受到了 Kolmogorov-Arnold 网络(KANs)在准确性和可解释性方面令人印象深刻的成果的启发,KANs 通过堆叠从 KolmogorovAnold 表示定理衍生出的非线性可学习激活函数重塑了神经网络学习。具体来说,在本文中,我们探索了 KAN 在改进视觉任务骨干方面尚未开发的潜力。我们通过在标记化中间表示上集成专用 KAN 层,研究、修改和重新设计了已建立的 U-Net 管道(称为 U-KAN)。严格的医学影像分割基准验证了 U-KAN 的优越性,即以更低的计算成本获得更高的精确度。我们进一步深入研究了 U-KAN 作为扩散模型中 U-Net 噪声预测器替代品的潜力,证明了它在生成面向任务的模型架构方面的适用性。这些努力揭示了宝贵的见解,并阐明了使用 U-KAN 可以为医学影像分割和生成提供强大支柱的前景。项目页面:https://yes-ukan.github.io/。
1 Introduction
过去十年间,在计算机辅助诊断和图像引导手术系统需求的推动下,许多研究工作都集中在开发高效、稳健的医学影像分割方法上[42, 44, 48, 51, 52, 77, 78]。其中,U-Net [71] 是一项具有里程碑意义的工作,它初步证明了具有跳连接的编码器-解码器卷积网络在医学图像分割方面的有效性 [13, 43, 84, 90]。近年来,UNet 已成为几乎所有主要医学图像分割方法的支柱,并在许多图像翻译任务中显示出良好的效果。此外,最近的扩散模型也利用了 U-Net,训练它迭代预测每个去噪步骤中要去除的噪声。
自 U-Net [71]问世以来,特别是在医学成像子领域,已经推出了一系列重要的改进,包括 U-Net++[94]、3D U-Net[12]、V-Net [60] 和 YNet [58]。U-NeXt[81] 和 Rolling U-Net[54] 整合了卷积运算和 MLP 的混合方法,以优化分割网络的功效,使其能在资源有限的医疗点部署。最近,许多基于transformer的网络被用于增强 U-Net 骨干网,以进行医学图像分割。这些网络在处理全局上下文和长程依赖性方面表现出了有效性[24, 68]。例如,Trans-UNet[9]采用 ViT 架构[14],利用 U-Net 进行二维医学影像分割;MedT[80]和 UNETR[23] 等其他基于transformer的网络也是如此。transformer虽然非常复杂,但在处理有限的数据集时往往会出现过拟合现象,这表明transformer对数据的需求很大[50, 79]。与此相反,结构化状态空间序列模型(SSM)[16, 18, 67]最近在长序列建模中显示出高效率和高效益,是视觉任务中长期依赖性建模的有前途的解决方案。在医学图像分割方面,U-Mamba [56] 和 SegMamba [88] 分别基于 nn-UNet [32] 和 Swin UNETR [22],提出了具有 Mamba 块的特定任务架构,在各种视觉任务中取得了可喜的成果,展示了 SSM 在视觉领域的潜力。
虽然现有的 U 形变体在医学图像分割等精细训练的医疗场景中取得了进展,但由于其核设计不够理想以及无法解释的性质,它们仍然面临着根本性的挑战。具体来说,首先,它们通常采用传统内核(*这类运算包括卷积、Transformers和MLP等)来捕捉局部像素之间的空间依赖性,这种内核仅限于线性建模潜空间中不同通道之间的模式和关系。这使得捕捉复杂的非线性模式面临挑战。这种通道间错综复杂的非线性模式在医学成像等视觉任务中非常普遍,因为图像通常具有错综复杂的诊断特征。这种复杂性意味着特征通道可能具有不同的临床相关性,代表不同的解剖成分或病理指标。其次,他们大多采用经验网络搜索和启发式模型设计来寻找最佳架构,忽略了现有黑盒 U 型模型的可解释性和可说明性。在现有的 U 型变体中,这种不可解释性给临床决策带来了很大风险,进一步阻碍了诊断系统设计的真理价值。最近,Kolmogorov-Arnold 网络(KANs)尝试以卓越的可解释性打开传统网络结构的黑箱,揭示了白箱网络研究的巨大潜力[64, 92]。考虑到 KAN 融合了出色的结构特性,有效利用 KAN 来弥合网络物理属性与经验性能之间的差距是有意义的。
在这一努力中,我们开始探索一种普遍适用的 U-KAN 框架(称为 U-KAN),这是通过卷积 KAN 混合架构风格将高级 KAN 集成到 UNet 关键视觉骨干的首次尝试。值得注意的是,在 U-Net 基准设置的基础上,我们采用了多层深度编码器-解码器跳转连接架构,并在接近瓶颈的高层表示中加入了新颖的标记化 KAN 块。该块将中间特征投射到标记(tokens)中,然后应用 KAN 运算符提取信息模式。拟议的 U-KAN 受益于 KAN 网络在非线性建模能力和可解释性方面的诱人特性,这使其在流行的 U-Net 架构中脱颖而出。在严格的医疗分割基准上进行的定量和定性实证评估突出表明了 U-KAN 的卓越性能,其准确性超过了现有的 U-Net 主干网,甚至不需要更少的计算成本。我们的研究进一步探讨了 U-KAN 作为扩散模型中 U-Net 噪声预测器替代品的潜力,证实了它在生成面向任务的模型架构方面的相关性。简而言之,U-KAN 标志着将数学理论启发的算子纳入高效视觉管道的设计迈出了坚实的一步,并预示着其在广泛视觉应用中的前景。我们的贡献可总结如下:
- 我们首次尝试结合新兴 KAN 的优势,改进现有的 U-Net 管道,使其更加准确、高效和可解释。
- 我们提出了一个标记化 KAN 模块,以有效引导 KAN 运算符(operators),使其与现有的基于卷积的设计兼容。
- 我们在广泛的医疗分割基准上对 U-KAN 进行了实证验证,取得了令人印象深刻的准确性和效率。
- 将 U-KAN 应用于现有的扩散模型,作为一种改进的噪声预测器,证明了它在后向生成任务和更广泛的视觉环境中的潜力。
2 Related work
2.1 U-Net Backbone for Medical Image Segmentation
医学图像分割是一项具有挑战性的任务,近年来深度学习方法已被广泛应用,并取得了突破性进展[40, 49, 62, 71, 77]。U-Net [71] 是一种用于医学图像分割的流行网络结构。其编码器-解码器结构能有效捕捉图像特征。CE-Net [20] 进一步整合了上下文信息编码模块,增强了模型的感受野和语义表征能力。Unet++ [94] 提出了一种嵌套 U-Net 结构,可融合多尺度特征以提高分割精度。除了基于卷积的方法,基于Transformer的模型也受到了关注。视觉Transformer [14] 证明了Transformer在图像识别任务中的有效性。医学Transformer[80]和 TransUNet [9]进一步将Transformer应用于医学图像分割,取得了令人满意的效果。此外,注意力机制[76]和多尺度特征融合[31]等技术也被广泛应用于医学图像分割任务中。多维门控循环单元[2]和高效多尺度三维 CNN [34]等三维分割模型也取得了可喜的成果。总之,医学图像分割是一个活跃的研究领域,深度学习方法在这一领域取得了重大进展。最近,Mamba[18]通过将选择机制和硬件感知算法整合到之前的作品[19, 21, 57]中,以其线性时间推理和高效的训练过程取得了突破性的里程碑。在 Mamba 成功的基础上,针对视觉应用,Vision Mamba [53] 和 VMamba [95] 分别使用双向 Vim Block 和 Cross-Scan Module 来获取依赖于数据的全局视觉上下文。同时,U-Mamba[56] 和其他作品[72, 88]在医学图像分割方面表现出了卓越的性能。由于 Kolmogorov-Arnold 网络(KAN)[55] 已被认为是 MLP 的理想替代品,并证明了其精确性、高效性和可解释性,我们认为现在是探索其在视觉骨干网中更广泛应用的合适时机。
2.2 U-Net Diffusion Backbone for Image Generation
扩散概率模型是生成模型的一个前沿类别,已成为研究领域的一个焦点,特别是在与计算机视觉相关的任务中[26, 69, 70]。与其他类别的生成模型[7, 17, 35, 36, 61, 83]不同,如变分自动编码器(VAE)[36]、生成对抗网络(GANs)[7, 17, 35, 93]和向量量化方法[15, 82],扩散模型引入了一种新的生成范式。这些模型采用固定的马尔可夫链来映射潜在空间,形成复杂的映射,捕捉数据集固有的复杂结构。最近,从高级细节到生成样本的多样性,这些模型的生成能力令人印象深刻,推动了各种计算机视觉应用取得突破性进展,如图像合成[26, 70, 74]、图像编辑[3, 11, 46, 59]、图像到图像翻译[11, 45, 73, 85]和视频生成[6, 25, 27, 41]。扩散模型由扩散过程和去噪过程组成。在扩散过程中,高斯噪声被逐渐添加到输入数据中,最终腐蚀成近似纯高斯噪声。在去噪过程中,原始输入数据通过学习到的反向扩散操作序列从其噪声状态中恢复出来。通常情况下,卷积 U-Nets [71] 是骨干架构的事实选择,通过对其进行训练,可以迭代预测在每个去噪步骤中需要去除的噪声。以往的工作侧重于将预先训练好的扩散 U-Nets 用于下游应用,与此不同的是,最近的工作致力于探索扩散 U-Nets 的内在特征和结构特性。Free-U 从战略角度重新评估了 U-Net 跳转连接和主干特征图的贡献,以充分利用 U-Net 架构中这两个组成部分的优势。RINs [33] 为 DDPMs 引入了一种基于注意力的新型高效架构。DiT [66] 提出了纯transformer 与扩散的结合,展示了其可扩展性。在本文中,我们展示了集成 U-Net 和 KAN 的生成骨干网方案的潜力,推动了生成骨干网的边界和选择。
2.3 Kolmogorov–Arnold Networks (KANs)
科尔莫哥罗夫-阿诺德定理[37]假定,任何连续函数都可以表示为有限变量的连续一元函数的组合,这为构建通用神经网络模型提供了理论基础。霍尼克等人[28]进一步证实了这一点,他们证明了前馈神经网络具有通用逼近能力,为深度学习的发展铺平了道路。学者们从科尔莫哥罗夫-阿诺德定理出发,提出了一种新颖的神经网络架构,即科尔莫哥罗夫-阿诺德网络(KANs)[29]。KANs 由一系列串联的 Kolmogorov-Arnold 层组成,每个层包含一组可学习的一维激活函数。事实证明,这种网络结构能有效逼近高维复杂函数,并在各种应用中表现出稳定的性能。KAN 具有很强的理论可解释性和可解释性。Huang 等人[30] 分析了 KAN 的优化特性和收敛性,验证了其出色的逼近能力和泛化性能。Liang 等人[47]进一步引入了深度 KAN 模型,并将其应用于图像分类等任务。Xing 等人[87]将 KAN 用于时间序列预测和控制问题。尽管取得了这些进展,但在将具有坚实理论基础的 KAN 新型神经网络模型广泛融入通用视觉网络方面,一直缺乏实际应用。与此相反,本文进行了初步探索,尝试设计一种整合 KAN 的通用视觉网络架构,并在广泛的分割和生成任务中进行验证。
3 Method
Architecture Overview 图 1 展示了拟议 U-KAN 的整体架构,该架构采用双阶段编码器-解码器架构,包括一个卷积阶段和一个标记化(tokenized ) Kolmogorov-Arnold 网络 (Tok-KAN) 阶段。输入图像经过编码器时,最初的三个块采用卷积运算,然后是两个标记化 MLP 块。解码器由两个标记化 KAN 块和三个卷积块组成。每个编码器块将特征分辨率减半,而每个解码器块将其加倍。此外,编码器和解码器之间还集成了跳转连接。卷积阶段和 Tok-KAN 阶段中每个区块的通道数分别由 至
和
至
这两个超参数决定。
3.1 KAN as Efficient Embedder
这项研究旨在将知识感知网络(KANs)纳入 UNet 框架,或者将 KANs 独立用于医学影像分割任务。这种方法的基础是 [55] 中概述的已被证实的 KANs 的高效性和可解释性。由 层组成的多层感知器 (MLP) 可以描述为转换矩阵
和激活函数
的相互作用。其数学表达式为
![]()
它通过多层次的非线性变换序列,努力模拟复杂的函数映射。尽管这种结构具有潜力,但其内在的模糊性极大地阻碍了模型的可解释性,从而对直观地理解潜在的决策机制构成了巨大挑战。
为了缓解 MLP 固有的参数效率低和可解释性有限的问题,Liu 等人[55]从 Kolmogorov-Arnold 表示定理[38]中汲取灵感,提出了 Kolmogorov-Arnold 网络 (KAN)。与 MLP 类似,K 层 KAN 可以被表述为多个 KAN 层的嵌套:
![]()
其中,表示整个 KAN 网络的第
层。每个 KAN 层有
维输入和
维输出,Φ 包括
个可学习的激活函数
:
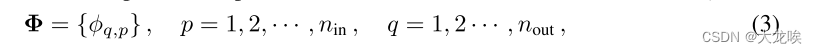
KAN 网络从第层到第
层的计算结果可以用矩阵形式表示:

总之,KAN 有别于传统的 MLP,它在边上使用可学习的激活函数,并将参数化的激活函数作为权重,从而无需线性权重矩阵。这种设计使 KANs 能够以较小的模型规模实现相当或更优的性能。此外,KANs 的结构在不影响性能的前提下增强了模型的可解释性,使其适用于各种应用。
3.2 U-KAN Architecture
3.2.1 Convolution Phrase
每个卷积块都由三部分组成:卷积层 (Conv)、批处理归一化层 (BN) 和 ReLU 激活函数。我们采用了3x3的核大小、1的步长和1的填充量。编码器中的卷积块集成了一个池窗口维度为 2x2 的最大池化层,而解码器中的卷积块则包含一个用于放大特征图的双线性插值层。从形式上看,给定一幅图像后,每个卷积块的输出可以表示为

其中,表示第
层的输出特征图。考虑到卷积阶段中有 L 个区块,最终输出结果为
。
3.2.2 Tokenized KAN Phrase
Tokenization 在标记化 KAN 模块中,我们首先通过将卷积阶段的输出特征重塑为扁平化二维补丁序列
来执行标记化 [10, 14],其中每个补丁的大小为
,
是特征补丁的数量。我们首先使用可训练的线性投影
将矢量化斑块
映射到潜在的 D 维嵌入空间,如图所示:
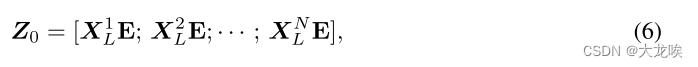
线性投影是由一个核大小为 3 的卷积层实现的,因为文献[86]表明,一个卷积层就足以对位置信息进行编码,而且它实际上比标准的位置编码技术性能更好。当测试分辨率和训练分辨率不同时,像 ViT 这样的位置编码技术需要进行内插,这往往会降低性能。
Embedding by KAN Layer 给定获得的令牌(tokens),我们将它们传递到一系列KAN 层(N=3)。在每个 KAN 层之后,特征会通过一个高效的深度卷积层(DwConv)[8] 和一个 bacth 归一化层(BN)以及 ReLU 激活。我们在此使用残差连接,并将原始标记(tokens)作为残差添加。然后,我们应用层归一化(LN)[4],并将输出特征传递给下一个区块。从形式上看,第 k 个标记化 KAN 代码块的输出可以表述为
![]()
其中,是第
层的输出特征图。鉴于标记化(Tokenized ) KAN 词组中有 K 个区块,最终输出为
。在我们的实现中,我们设置
。
3.2.3 U-KAN Decoder
我们采用常用的 U 型结构,通过密集的跳转连接来构建 U-KAN 网络。U-Net 及其变体在医学图像分割任务中表现出了显著的效率 [39、89、91]。这种结构利用跳转连接恢复低级细节,并采用编码器-解码器结构提取高级信息。
给定 KAN 阶段 中第层的跳转连接特征
和最后一个上采样块的特征
,则第 k 个上采样块的输出特征
:
![]()
其中表示特征连接操作。同样,给定卷积阶段中来自层
的跳接连接特征
和来自最后一个上采样块的特征
,则第
个上采样块的输出特征
为:
![]()
在语义分割任务中,最终的分割图可以从第 0 层的输出特征图得出,其中
是语义类别数,
表示地面实况分割和。因此,分割损失可以是

其中,表示像素方向的交叉熵损失。
3.3 Extending U-KAN to Diffusion Models
以上讨论的重点是通过 U-KAN 生成输入图像的分割掩码。在本节中,我们将进一步把 U-KAN 扩展到扩散版本,即扩散 U-KAN,从而释放 KAN 的生成能力。根据扩散概率模型(Denosing Diffusion Probabilistic Models,DDPM)[26],扩散 U-KAN 能够通过逐渐去除噪声,从随机高斯噪声
中生成图像。这个过程可以通过预测给定噪声输入的噪声来实现:
,其中
是被高斯噪声
破坏的图像
,
,
是控制噪声强度的时间步长,并且
。
为此,我们在分段 U-KAN 的基础上进行了两处修改,将其提升为扩散版本。首先,与只在不同隐藏层之间传播特征不同,我们在每个区块中注入可学习的时间嵌入,使网络具有时间感知能力(见图 1 中虚线 "时间嵌入"),并移除 DwConv 和残差连接,从而将公式 7 变为以下格式,以实现生成任务的目标:
![]()
其中,线性投影,
表示给定时间步长
的时间嵌入[26]。其次,我们修改了预测目标,以实现基于扩散的图像生成。Diffusion U-KAN 的目标不是预测给定图像的分割掩码,而是预测给定噪声干扰图像
和随机时间步长
的噪声
:

通过上述损失函数进行优化后,使用 DDPM 采样算法 [26] 生成图像,利用训练有素的扩散 U-KAN 进行去噪。
4 Experiments
4.1 Datasets
我们在三个不同的异构数据集上对我们提出的方法进行了全面评估,每个数据集都具有独特的特征、不同的数据大小和不同的图像分辨率。这些数据集通常用于图像分割和生成等任务,为我们方法的有效性和适应性提供了强大的测试平台。
BUSI BUSI 数据集 [1] 由描述正常、良性和恶性乳腺癌病例的超声波图像以及相应的分割图组成。在研究中,我们使用了 647 幅超声图像,分别代表良性和恶性乳腺肿瘤。所有这些图像的尺寸均调整为 256×256。该数据集提供了一个全面的图像集合,有助于检测和区分各种类型的乳腺肿瘤,为医疗专业人员和研究人员提供有价值的见解。
GlaS GlaS 数据集[80]由来自 31 个序列的 612 个标准清晰度(SD)帧组成。每个帧的分辨率为 384 × 288,采集自 23 名患者。该数据集与位于西班牙巴塞罗那的医院诊所有关。该数据集中的序列是使用奥林巴斯 Q160AL 和 Q165L 等设备以及 Extra II 视频处理器记录的。我们的研究特别使用了 GlaS 数据集中的 165 幅图像,所有图像均调整为 512 × 512 尺寸。
CVC-ClinicDB CVC-ClinicDB 数据集[5]通常简称为 "CVC",是结肠镜视频中息肉诊断的公开资源。该数据集共包含 612 幅图像,每幅图像的分辨率为 384 × 288,是从 31 个不同的结肠镜检查序列中精心提取的。这些帧提供了各种息肉实例,因此对息肉检测算法的开发和评估特别有用。为了确保研究中使用的不同数据集的一致性,CVC-ClinicDB 数据集中的所有图像都统一调整为 256 × 256 大小。
4.2 Implementation Details
Segmentation U-KAN 我们在英伟达 RTX 4090 GPU 上使用 Pytorch 实现了 U-KAN。对于 BUSI、GlaS 和 CVC 数据集,批次大小设置为 8,学习率为 1e-4。我们使用 Adam 优化器训练模型,并使用余弦退火学习率调度器,最小学习率为 1e-5。损失函数是二元交叉熵(BCE)和骰子(dice )损失的组合。我们将每个数据集随机分成 80% 的训练子集和 20% 的验证子集。这些数据集的所有结果都是通过三次随机运行得出的。只应用了包括随机旋转和翻转在内的香草(vanilla )数据增强。我们总共对模型进行了 400 次历时训练。我们使用 IoU 和 F1 Score 等各种指标对输出的分割图像进行了定性和定量比较。我们还报告了与计算成本相关的指标,如 Gflops 和参数数 (Params)。
Diffusion U-KAN 图像被裁剪并调整为 64 × 64,用于无条件生成。我们在相同的训练设置下对所有方法进行了基准测试: 1e-4 学习率、1000 个历时、亚当(Adam)优化器和余弦退火学习率调度器。为了评估每种方法的生成能力,我们使用随机高斯噪声作为输入,生成 2048 个图像样本。然后,我们使用各种指标,如弗雷谢特入门距离(FID)[65] 和入门分数(IS)[75],对生成的图像进行定性和定量比较。这些指标可帮助我们深入了解生成图像的多样性和质量。
4.3 Comparison with State-of-the-arts on Image Segmentation
表 1 列出了所提出的 U-KAN 在所有基准数据集上与所有比较方法的结果。我们将 U-KAN 与最近流行的医学图像分割框架进行了比较,并与 U-Net[71]、U-Net++[94] 等卷积基线模型进行了基准比较。我们还评估了基于注意力的对应模型的性能,包括 Att-UNet [63] 和最先进的高效transformer 变体 U-Mamba [56]。此外,由于 KAN 是 MLP 的一种有前途的替代品,我们还进一步与基于 MLP 的高级分割网络进行了比较,包括 U-Next [81] 和 Rolling-UNet [54]。在性能指标方面,我们使用了两个标准指标来评估图像分割任务,包括交集大于联合(IoU)和 F1 分数。结果表明,在所有数据集上,我们的 U-KAN 的性能都超过了所有其他方法。
除了准确性方面的优势,本文还进一步证明了我们的方法在用作网络基线时的效率。如表 2 所示,我们报告了模型在各种数据集上的参数量(M)和 Gflops,以及分割精度。结果表明,除 UNext 外,我们的方法不仅在分割准确率方面超越了大多数分割方法,而且在效率方面也表现出显著优势或相当水平。总体而言,在分割准确性和效率的权衡中,我们的方法表现最佳。
我们进一步对所有数据集进行了全面的定性比较,如图 2 所示。首先,从结果可以看出,基于纯 CNN 的方法(如 U-Net 和 UNet++)更容易对器官进行过度或不足分割,这表明这些模型在编码全局上下文和区分语义方面存在局限性。相比之下,我们提出的 UKAN 与其他方法相比产生的误报较少,这表明它在抑制噪声预测方面具有优势。与基于Transformers的模型和基于 MLP 的高效架构相比,U-KAN 的预测往往在边界和形状方面表现出更精细的细节。这些观察结果凸显了 U-KAN 在保留复杂形状信息的同时进行精细分割的能力。这进一步证实了我们最初的直觉,凸显了加入 KAN 层所带来的优势。
4.4 Comparison with State-of-the-arts on Image Generation
我们研究了我们提出的 U-KAN 作为生成任务骨干的潜力。我们将 U-KAN 与各种扩散变体模型(均基于传统的 U-Nets)进行了比较,以评估该架构在不同生成任务中的功效。结果如表 3 所示,我们报告了三个数据集的 FID [65](弗雷谢特起始距离)和 IS [75](起始分数)指标。弗雷谢特感知距离是两个分布之间距离的度量,这里指的是生成图像的分布和真实图像的分布之间的距离。FID 越小,表示生成的图像与真实图像越相似。另一方面,"入门分数"(Inception Score)通过评估生成的图像能被归入特定类别的程度来衡量图像的质量。IS 越高,说明生成的图像分类正确率越高。实验结果清楚地表明,与该领域其他最先进的模型相比,我们的方法表现出更优越的生成性能。这表明我们的 U-KAN 架构特别适合生成任务,为生成高质量图像提供了一种有效且高效的方法。
4.5 Ablation Studies
为了全面评估所提出的 TransUNet 框架并验证其在不同设置下的性能,我们进行了以下各种消融研究。
The Number of KAN Layer 如前所述,在 U-KAN 中加入 KAN Layers 已被证明是有益的,它通过明确加入高效嵌入,促进了更精细的分割细节建模。本次消融研究的目的是评估加入不同数量的 KAN 层的影响。我们将 KAN 层的数量从 1 个调整为 5 个,如表 4 所示。从表 4 中可以看出,含有三个 KAN 层的配置性能最为优越。这些结果证实了我们最初的假设,即在 U-KAN 中战略性地整合足够数量的 KAN 层可以有效捕捉与细分相关的复杂细微差别。
Impact on Using KAN Layer v.s. MLP 为了进一步证实 KAN 层在提高模型性能方面的作用,我们进行了一系列消融实验,如表 5 所示。在这些实验中,我们用传统的多层感知器(MLP)替换了引入的 KAN 层,以观察这种修改是否会导致性能下降。通过这种方法,我们可以更直观地理解 KAN 层在提高模型可解释性和整体性能方面的重要作用。起初,我们修改了一个已经包含 KAN 层的模型,用标准 MLP 取代了一个或多个 KAN 层。随后,我们使用相同的数据集和训练参数对修改后的模型进行了重新训练,并记录了其在各种任务中的表现。结果表明,用 MLP 代替 KAN 层后,多项任务的性能明显下降,尤其是在需要强大特征提取和表征能力的复杂任务中。这些发现强调了 KAN 层在增强模型表达能力和提高整体性能方面的关键作用。
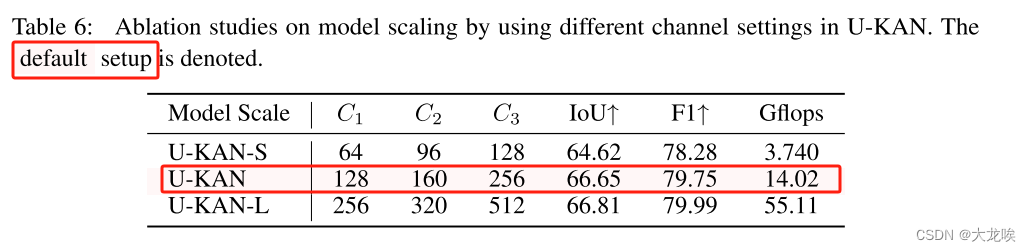
Model Scaling 最后,我们对不同尺寸的 U-KAN 模型进行了消融研究。具体来说,我们研究了 U-KAN 的其他配置,分别称为小型和大型模型。这些变体的主要区别在于它们的通道设置,即从第一层到第三层 KAN 层(C1-C3)的不同通道数,详见表 6。小型模型的通道设置为 64-96-128,而大型模型的通道数设置为 256-320-512。相比之下,我们默认模型的通道数配置为 128-160-256。我们观察到,大型模型与性能增强相关,这与集成 KAN 的模型所表现出的缩放规律特征一致。最终,为了在性能和计算费用之间取得平衡,我们选择在实验中使用默认的基本模型。
5 Conclusion
本文介绍了 U-KAN,并展示了 Kolmogorov-Arnold 网络(KAN)在增强 U-Net 等骨干网以实现各种视觉应用方面的巨大潜力。通过将 KAN 层集成到 U-Net 架构中,可以为视觉任务提供一个强大的网络,在准确性、效率和可解释性方面都令人印象深刻。我们在多个医学图像分割任务中对我们的方法进行了实证评估。此外,U-KAN 的适应性和有效性也凸显了它作为 U-Net 的替代品,在扩散模型噪声预测方面的潜力。这些发现强调了探索 KAN 等非传统网络结构对于推动更广泛视觉应用的重要性。
图
图 1:U-KAN 管道概览。在通过卷积阶段中的多个卷积块进行特征提取后,中间映射将被标记化,并通过标记化(Tokenized ) KAN 词组中的堆叠 Tok-KAN 块进行处理。只有在应用扩散 U-KAN 时,才会在 KAN 块中注入时间嵌入。
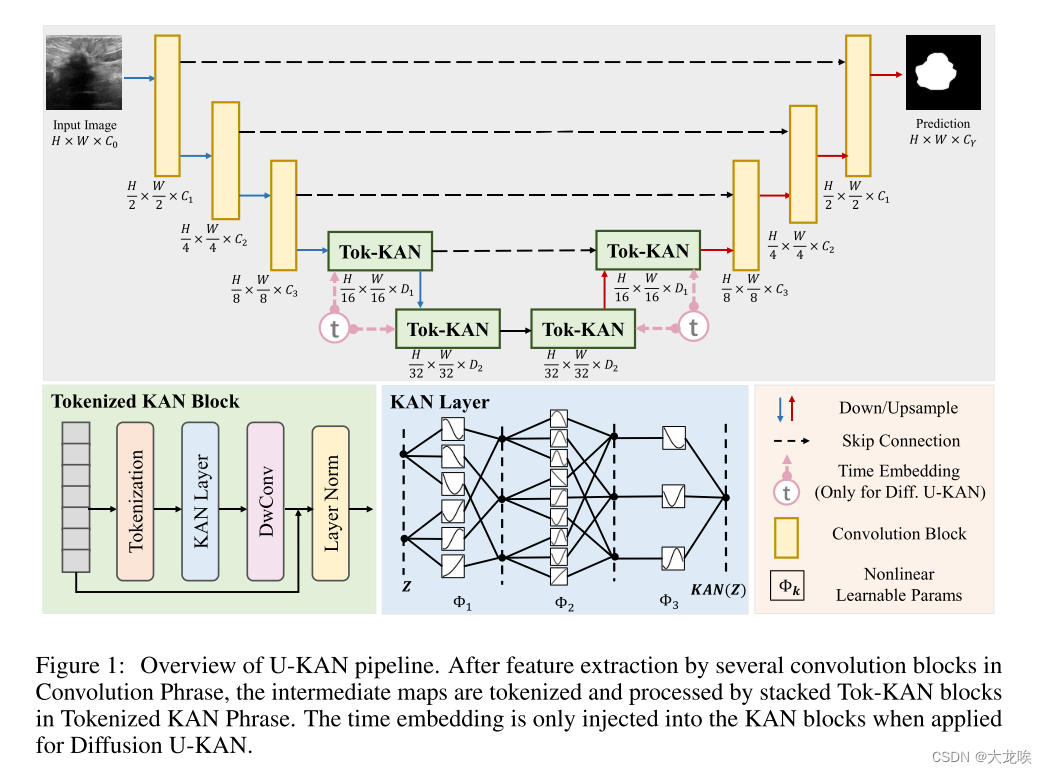
图 2:提出的 U-KAN 在三种异构医疗场景中与其他先进技术的可视化分割结果。

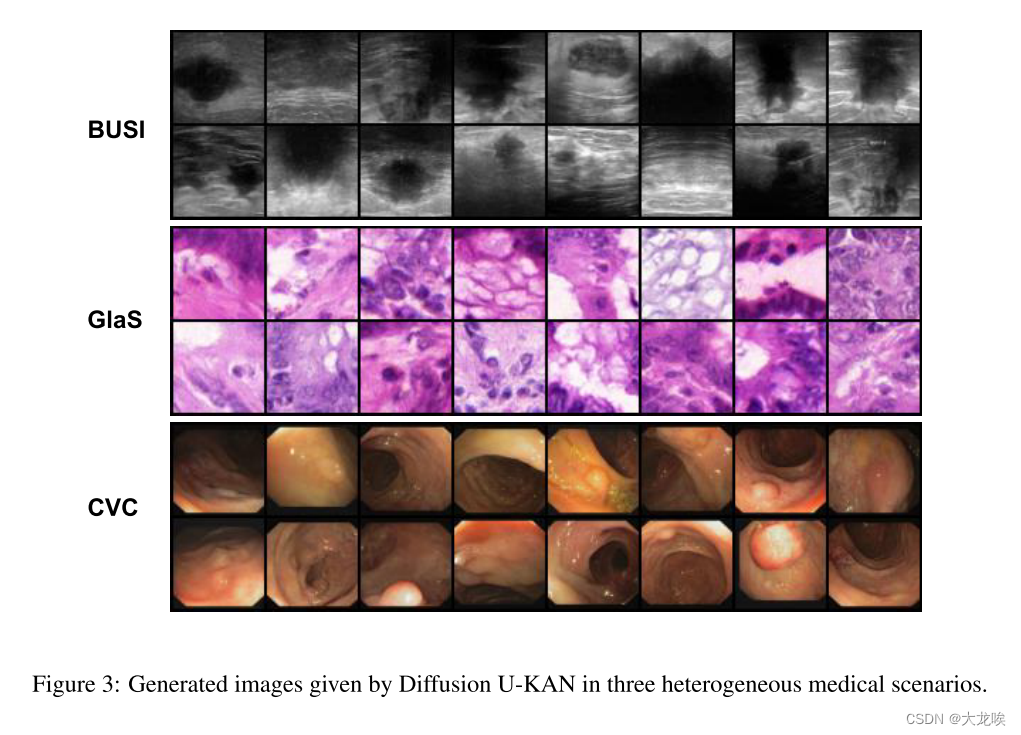
图 3:扩散 U-KAN 在三种异构医疗场景中生成的图像。
表
表 1:在三种不同的医疗场景中与最先进的分割模型进行比较。报告了三次随机运行的平均结果和标准偏差。
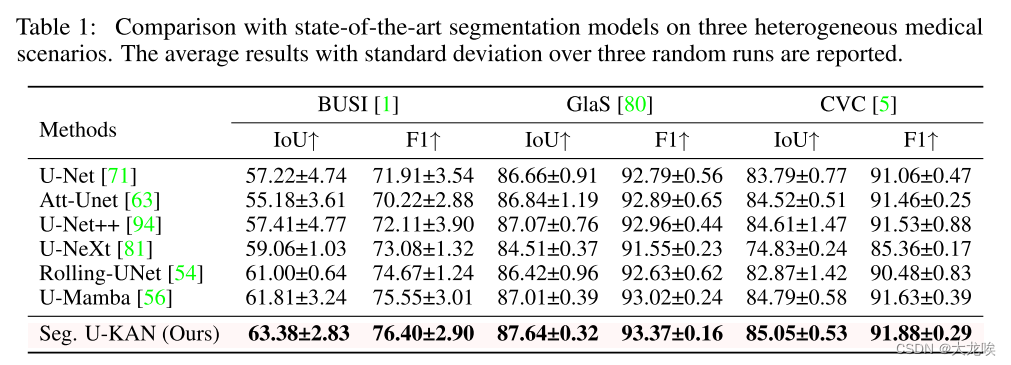
表 2: 与最先进的分割模型在效率和分割指标方面的总体比较。

表 3:与基于标准 U-Net 的扩散模型在三种异构医疗场景中的比较。为进行综合评估,我们提供了 Diffusion U-Net 不同变体的结果。

表 4:关于所用 KAN 层数的消融研究。
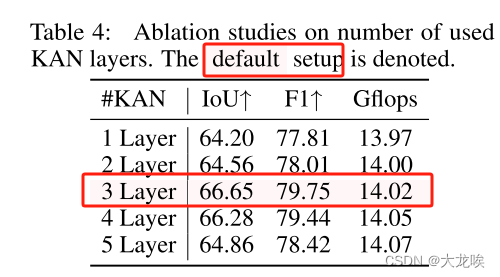
表 5:使用 KAN 层对 MLP 进行的消融研究。
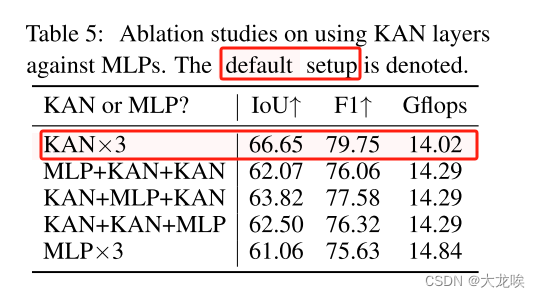
表 6:在 U-KAN 中使用不同通道设置对模型缩放进行的消融研究。






![# [0701] Task05 策略梯度、Actor-critic 算法](https://img-blog.csdnimg.cn/direct/a0a9570463e4479bb862d2edf0690624.png)